Chapter 13: VLA 모델 — 보고 듣고 행동하기
개요
VLA(Vision-Language-Action) 모델은 대규모 비전-언어 모델(VLM)에 로봇 행동을 결합하여, 보고(vision), 이해하고(language), 행동하는(action) 범용 로봇 제어를 추구합니다. 2023년 RT-2에서 시작된 이 패러다임은 2026년 현재 모든 주요 휴머노이드 로봇의 "뇌"로 채택되고 있습니다. 이 챕터에서는 VLA 계보, pi0 [#2]의 Flow Matching, 배치 후 개선, 촉각 통합, 그리고 스케일링 전략을 다룹니다.
이 챕터를 읽고 나면... - RT-1에서 Gemini Robotics까지 VLA 계보의 핵심 전환점을 설명할 수 있습니다. - pi0의 VLM + Flow Matching 아키텍처를 이해합니다. - 촉각이 VLA에 통합되는 방식과 의의(ForceVLA [#1], Tactile-VLA)를 파악합니다. - Open X-Embodiment의 교차 체현 데이터 전략을 설명할 수 있습니다.
13.1 VLA 계보: RT-1에서 Gemini Robotics까지
VLA 모델의 진화는 로봇 학습의 패러다임 전환을 반영합니다:
RT-1 (2023)
Google / Everyday Robots의 RT-1 [2]은 최초의 대규모 실세계 로봇 Transformer입니다:
- 130K 에피소드, 13대 로봇에서 학습
- 실세계 제어를 위한 대규모 Transformer의 가능성 입증
- 800회+ 인용 (RSS 2023)
RT-2 (2023)
Google DeepMind의 RT-2 [2]는 VLA 패러다임의 시작점입니다:
- 대규모 VLM (PaLI-X, PaLM-E)을 로봇 시연 데이터로 미세 조정
- 웹 지식(web knowledge)을 로봇 제어로 전이
- "사과를 집어"라는 언어 명령을 실행 가능
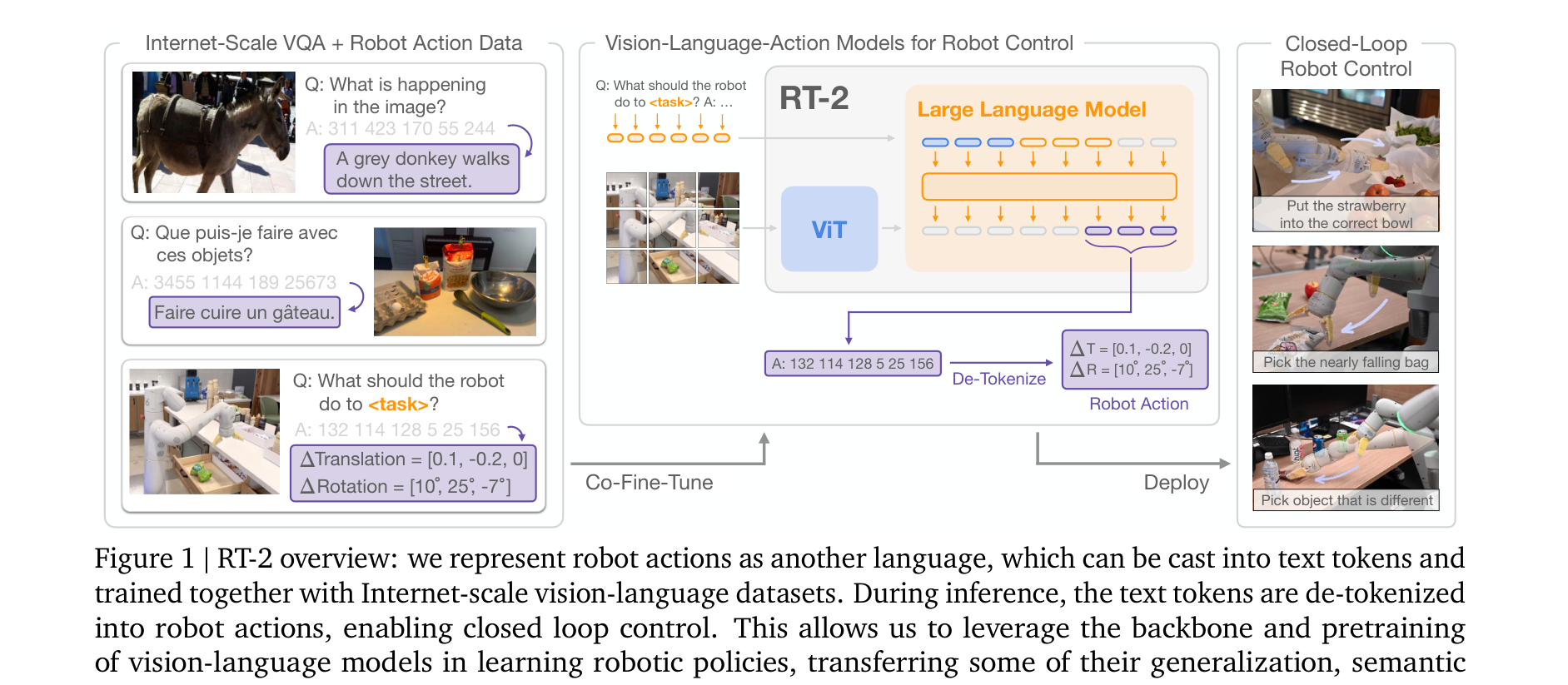
핵심 논문: Brohan et al. 2023. "RT-2: Vision-Language-Action Models Transfer Web Knowledge to Robotic Control." CoRL 2023. VLA 패러다임을 확립한 기념비적 논문. 대규모 VLM의 시각-언어 지식이 로봇 행동으로 전이될 수 있음을 최초로 입증했습니다.
OpenVLA (2024)
Stanford/DeepMind의 OpenVLA [3]는 오픈소스 VLA의 시작입니다:
- 7B 파라미터 — RT-2-X의 1/10 크기
- Open X-Embodiment로 학습
- RT-2-X를 성능에서 능가
- 가중치, 코드, 데이터 완전 오픈소스
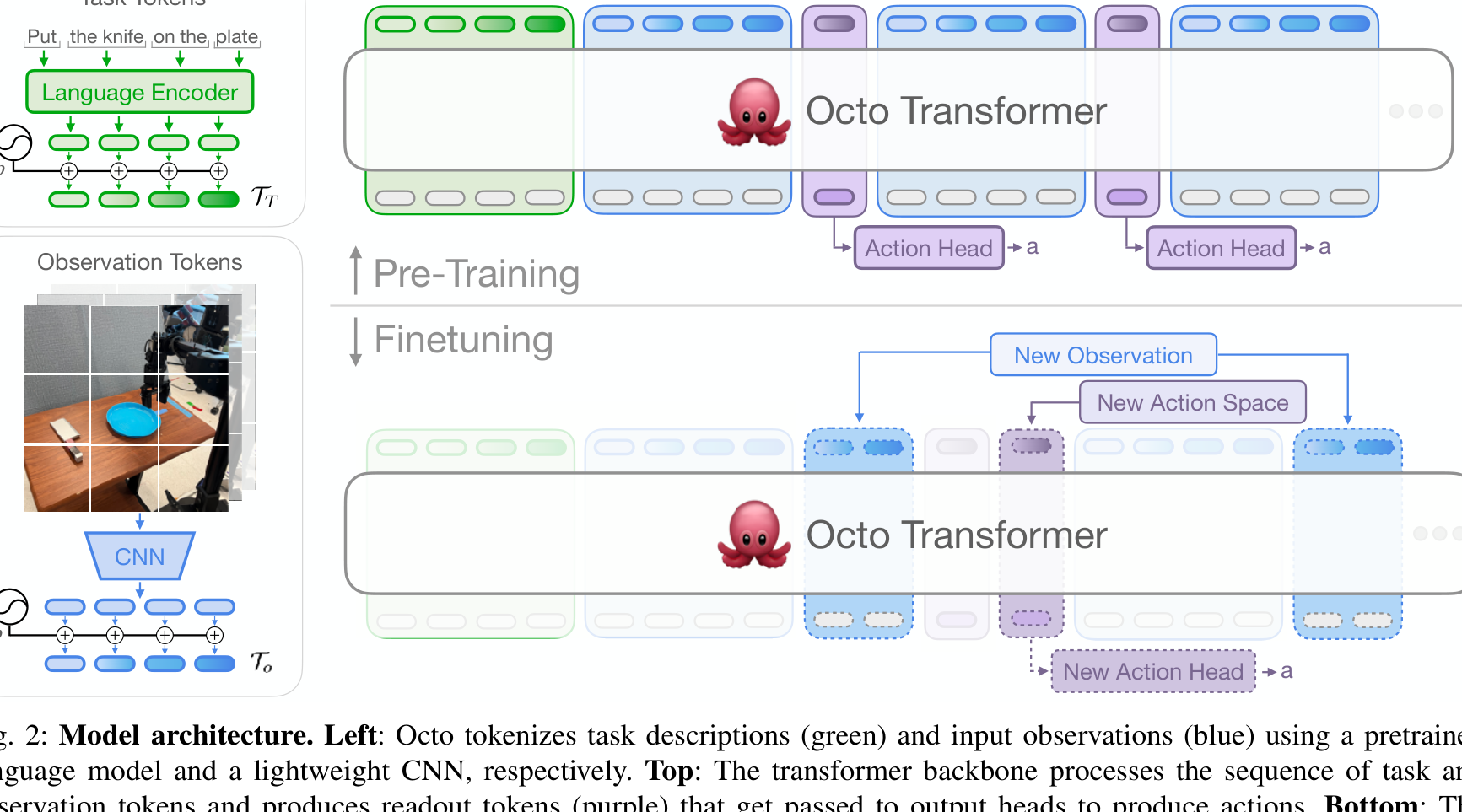
Octo (2024)
UC Berkeley의 Octo[4]는 범용 로봇 정책입니다:
- Transformer 기반 확산 정책(diffusion policy)
- 800K 에피소드로 사전학습
- 유연한 태스크/관찰 정의 지원
- 빠른 미세 조정(finetuning)
13.2 pi0: VLM + Flow Matching
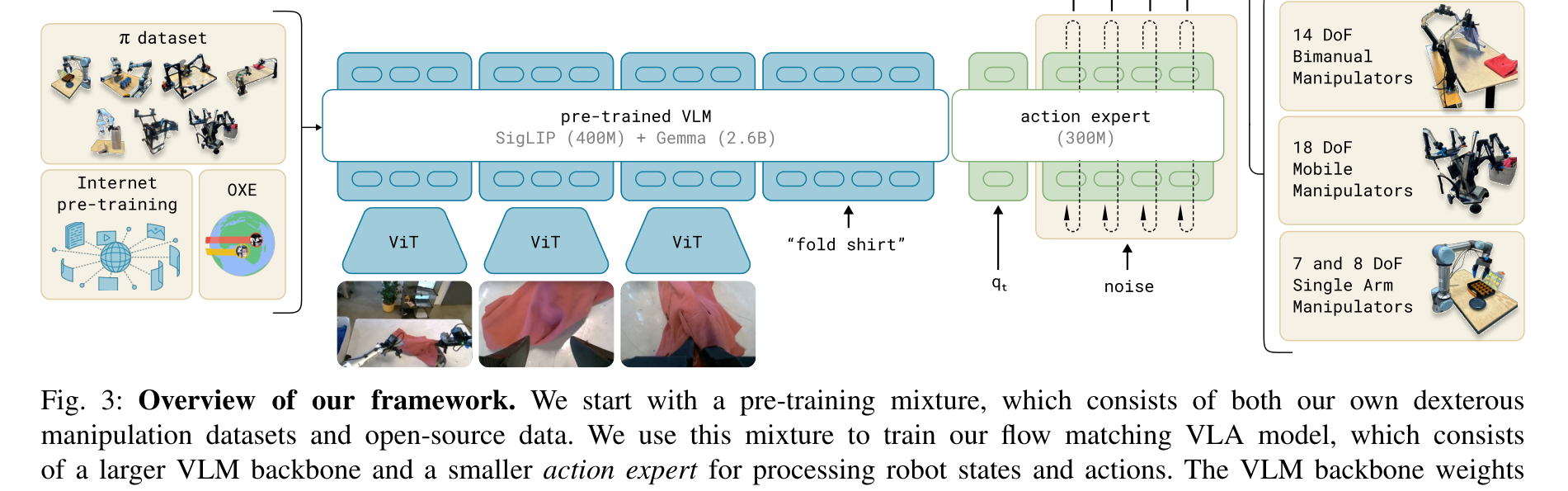
Physical Intelligence의 pi0 [5]은 VLA의 현 최선 사례 중 하나입니다:
- PaLiGemma 3B VLM 백본
- Flow Matching 행동 전문가: 연속 정규화 흐름(continuous normalizing flow)으로 행동 생성
- 7대 로봇, 68개 태스크, 10,000시간+ 데이터
- 사전학습 → 후학습 2단계 레시피
핵심 논문: Black, K., et al. (2024). "pi0: A Vision-Language-Action Flow Model for General Robot Control." arXiv:2410.24164. PaLiGemma VLM + Flow Matching으로 8개 체현(embodiment)에 걸친 범용 로봇 제어. 사전학습-후학습의 2단계 레시피가 핵심입니다.
pi0의 핵심 혁신은 Flow Matching [8]을 행동 생성에 적용한 것입니다. 기존 확산 모델(diffusion model)과 달리, flow matching은 시뮬레이션 없이 연속 정규화 흐름을 학습하여 더 효율적인 행동 생성을 가능하게 합니다.
13.3 pi0.6/RECAP: 배치 후 강화학습으로 지속 개선
pi0.6[15] [#4]와 RECAP은 배치 후(post-deployment) 강화학습으로 VLA의 지속 개선을 실현합니다:
- 초기 pi0으로 배치 → 실패/성공 데이터 수집
- 수집된 데이터로 RL 미세 조정
- 배치-학습-개선의 선순환(data flywheel)
이 접근은 VLA의 근본적 한계 — 시연 데이터 분포 외에서의 실패 — 를 배치 후 지속 학습으로 극복합니다. 세미나 3에서 논의된 "Sensing & Learning 동향"의 최전선입니다.
pi0 Human-to-Robot Transfer (2025)
Physical Intelligence [Dec 2025]는 pi0에 인간 데이터 공동 미세조정(human co-finetuning)을 적용하여:
- 4개 일반화 시나리오에서 2배 성능 개선
- Emergent alignment: 인간/로봇 데이터를 함께 학습하면 명시적 리타게팅 없이 자연스러운 정렬이 발생
- 이 발견은 Chapter 15.6의 co-training 접근(EgoMimic, EgoScale)과 일관된 결론
EgoVLA (2025)
EgoVLA [arXiv Jul 2025]는 egocentric 인간 비디오로 사전학습 후 로봇에 미세 조정하는 VLA입니다:
- 인간 egocentric 비디오에서 MANO [#17] hand parameter 기반 행동 표현 학습
- 인간 손 → 로봇 손의 표현 정렬을 VLA 프레임워크 내에서 해결
- Chapter 6.1의 MANO 모델과 Chapter 15의 retargeting 접근을 VLA에 통합
PhysBrain (2025)
PhysBrain [arXiv Dec 2025]은 대규모 VQA 데이터셋으로 VLM을 물리 세계에 맞춰 미세 조정합니다:
- Ego4D/BuildAI에서 3M VQA 쌍 생성
- VLM fine-tune → 53.9% SimplerEnv 성공률
- 인간 egocentric 비디오가 VLA의 물리적 상식(physical common sense) 학습에 효과적임을 입증
13.4 촉각 통합: ForceVLA, Tactile-VLA
VLA에 촉각/힘 정보를 "일급 모달리티(first-class modality)"로 통합하는 방향이 부상하고 있습니다.
ForceVLA (2025)
Yu et al.[6]의 ForceVLA (→ Chapter 12.4에서 소개):
- FVLMoE: 4개 전문가(expert)의 동적 라우팅
- pi0 기반 VLA에 힘 센서 정보 통합
- 힘 없는 기준 대비 +23.2%p 향상
- 시각 가림 시 90% 성공률
Tactile-VLA (2025)
Tactile-VLA[10]는 VLA의 물리 지식(physical knowledge)을 촉각으로 해방시킵니다:
- VLA의 사전학습된 시각-언어 지식이 촉각 일반화에 기여
- 접촉이 풍부한(contact-rich) 태스크에서 일반화 향상
촉각 통합의 도전
VLA에 촉각을 통합할 때의 핵심 도전은 시간 해상도 불일치입니다:
- 시각: ~30 Hz
- 힘/촉각: 100-1,000 Hz
- Transformer 지연(latency): 추론 시 실시간 제약
ForceVLA의 MoE 접근은 이 불일치를 동적 라우팅으로 부분적으로 해결하지만, 근본적 해법은 아직 열린 문제입니다 (→ Chapter 18.1 참조).

13.5 스케일링과 데이터: Open X-Embodiment
VLA의 성능은 데이터 규모에 강하게 의존합니다. Open X-Embodiment [2024, ICRA]는 이 문제의 핵심 해법입니다:
- 1M+ 궤적: 34개 연구실에서 수집
- 22개 체현(embodiment): 다양한 로봇 형태
- RT-1-X: 교차 체현 학습으로 50% 향상
- RT-2-X: 성능 3배 향상
- 300회+ 인용
핵심 논문: Open X-Embodiment Collaboration 2024. "Open X-Embodiment: Robotic Learning Datasets and RT-X Models." ICRA 2024. 34개 연구실의 1M+ 궤적을 통합한 최대 오픈소스 로봇 데이터셋. 교차 체현 학습의 위력을 입증했습니다.
NVIDIA의 합성 데이터 파이프라인도 핵심 역할을 합니다: 780K 궤적(6,500시간 상당)을 11시간에 생성하여 실제 성능 40% 향상. GR00T N1 [2025]은 세계 최초의 오픈 휴머노이드 Foundation Model로, 교차 체현 VLA를 조작에 적용합니다. GR00T N1.6 [2026]은 Cosmos Reason을 통한 추론(reasoning) 능력을 추가했습니다.

13.6 VLA의 한계와 전망
현재 한계
VLA Systematic Review [2026, Information Fusion]는 102개 모델, 26개 데이터셋, 12개 시뮬레이션 플랫폼을 분석하여 다음 한계를 식별합니다:
- 교차 태스크 일반화 부족: ICLR 2026의 164편 VLA 논문 분석에서 교차 태스크 일반화는 아직 미흡
- 장기 태스크(long-horizon) 실패: 5-30초 이상의 다단계 태스크에서 오차 누적
- 개방 세계(open-world) 물체: 학습 데이터에 없는 물체에서 실패
- 물성(material property) 미반영: 시각만으로는 마찰, 유연성 등을 추론할 수 없음 — 촉각 통합의 근거
아키텍처 설계 원칙
"What Matters in Building VLA Models" [2025, Nature Machine Intelligence]는 체계적 분석을 통해:
- 계층적/후기 융합(hierarchical/late fusion) 아키텍처가 최선의 일반화
- 확산 디코더(diffusion decoder)가 행동 생성에 최적
- 이 두 원칙은 ForceVLA의 MoE 아키텍처와 일치
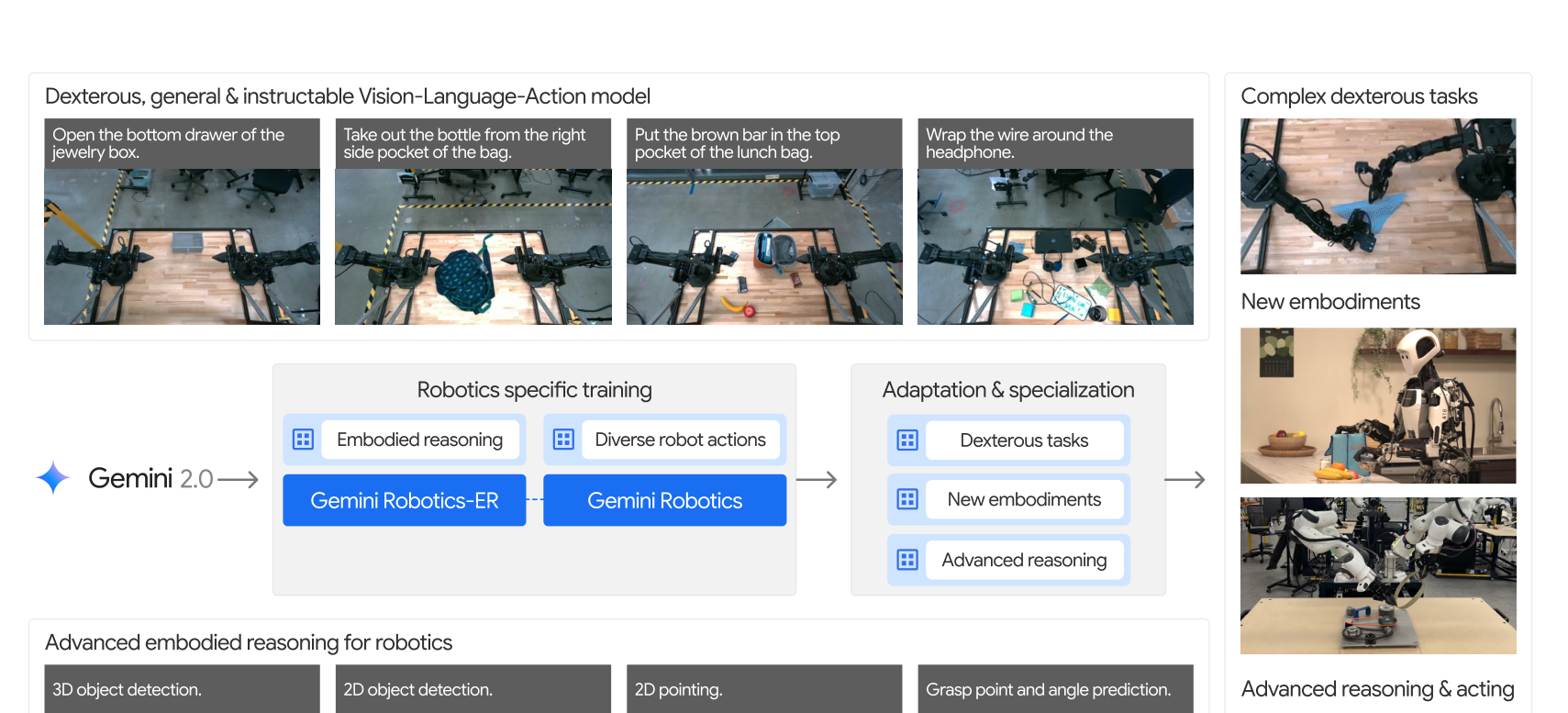
Gemini Robotics (2025)
Google DeepMind의 Gemini Robotics[6]는 Gemini 2.0 기반 VLA 패밀리입니다:
- Gemini Robotics-ER: 공간 이해, 파지 예측 포함 체현 추론(embodied reasoning)
- 다지 조작을 위한 정밀 제어
- "범용 로봇 뇌"를 향한 가장 야심적 시도
전망: 8가지 산업 트렌드 중 첫 번째
Chapter 17에서 상세히 다루겠지만, "VLA as Standard Brain"은 현재 8가지 산업 트렌드 중 첫 번째입니다. 모든 주요 휴머노이드 — Figure의 Helix, NVIDIA의 GR00T, Google의 Gemini, Physical Intelligence의 pi0 — 가 VLA 아키텍처를 채택하고 있습니다.
요약 및 전망
VLA 모델은 RT-1의 가능성 입증에서 pi0의 범용 제어, Gemini Robotics의 체현 추론까지 급속히 진화하고 있습니다. Open X-Embodiment의 교차 체현 데이터와 NVIDIA의 합성 데이터가 규모를 해결하고, ForceVLA와 Tactile-VLA가 촉각을 일급 모달리티로 통합하며, pi0.6/RECAP이 배치 후 지속 개선을 실현합니다.
그러나 장기 태스크, 개방 세계 일반화, 시각-촉각 시간 정렬 등 핵심 과제가 남아 있습니다. 이러한 과제들은 Chapter 18에서 체계적으로 다룹니다.
다음 챕터에서는 VLA와 RL 정책을 현실에 전이하는 Sim-to-Real 전이를 다룹니다 (→ Chapter 14 참조).
제조 셀 적용 체크포인트
VLA와 tactile sensing을 결합할 때 가장 중요한 질문은 tactile stream을 어디에서 소비할 것인가입니다. 모든 taxel 값을 거대한 모델에 그대로 넣는 방식은 데이터와 latency 비용이 큽니다. 반대로 tactile을 후처리 로그로만 남기면 contact-rich failure를 실시간으로 막을 수 없습니다. 실용적인 구조는 tactile raw data를 빠른 reflex와 contact summary로 나누고, VLA는 contact state, slip history, force-limit violation 같은 압축된 표현을 받는 것입니다.
제조 셀에서는 VLA가 성공 영상을 흉내 내는 것보다 실패 후 개선 루프에 들어가는지가 중요합니다. tactile log가 grasp candidate, SKU, pose estimate, operator override와 연결되어야 RECAP류의 post-deployment update나 S6/S9의 제조 data flywheel이 작동합니다. 이 관점에서 촉각은 VLA의 추가 모달리티가 아니라, 공정 안전 gate이자 실패 원인 라벨러입니다.
실전 적용 메모
이 장의 핵심은 VLA와 촉각 통합을 하나의 연구 키워드로만 보지 않고, 실제 로봇핸드 시스템에서 어떤 결정을 바꾸는지 묻는 데 있습니다. 실험을 설계할 때는 먼저 관측 가능한 상태를 정해야 합니다. 어떤 센서 값이 contact state, slip margin, force limit, object pose, operator override 중 무엇을 설명하는지 명확하지 않으면, 성공률이 높아도 다음 개선 루프가 막힙니다.
두 번째는 기록 단위입니다. 논문 데모는 성공 장면을 보여주지만, 제조형 연구는 실패를 재현 가능한 record로 남겨야 합니다. attempt id, task phase, hardware configuration, calibration version, tactile summary, policy output, human intervention을 함께 저장해야 다른 장에서 설명한 데이터 표현, 제어, 학습, 전이가 서로 연결됩니다.
마지막으로 이 장의 내용을 적용할 때는 "가장 성능이 좋은 방법"보다 "어떤 실패를 줄이는 방법인가"를 먼저 물어야 합니다. 촉각 로봇핸드의 실용성은 센서, 핸드, 정책, 시뮬레이터가 각각 좋은지보다, 실패 원인을 나누고 다음 실험을 더 싸게 만드는지에서 드러납니다.
장별 구현 프레임워크
VLA와 촉각 통합을 실제 시스템으로 옮길 때 첫 단계는 상태 정의입니다. 이 장에서 다루는 개념은 추상적인 성능 지표가 아니라, controller와 logger가 함께 읽을 수 있는 state variable이어야 합니다. 예를 들어 contact state, normal force, shear vector, slip margin, object pose, task phase, operator override, product-damage flag가 각각 어느 좌표계와 어느 시간 해상도에서 저장되는지 정해야 합니다. 이 정의가 없으면 정책이 성공하더라도 왜 성공했는지 알기 어렵고, 실패했을 때도 planner, controller, sensor, hardware, operator workflow 중 어느 부분을 고쳐야 하는지 분리할 수 없습니다.
두 번째 단계는 제어 루프를 시간 규모별로 나누는 것입니다. 빠른 루프는 200-1000 Hz에서 force derivative, shear spike, motor current, joint torque를 처리합니다. 중간 루프는 20-100 Hz에서 contact pose, grasp phase, reference finger motion을 갱신합니다. 느린 루프는 1-10 Hz에서 task instruction, object identity, SKU, fixture state, next grasp candidate를 판단합니다. VLA와 촉각 통합이 어느 루프에 들어가는지 명확해야 VLA, MPC, tactile reflex, residual policy가 서로 다른 일을 하면서도 같은 목표를 향해 작동합니다. 모든 정보를 하나의 거대 정책에 넣는 방식은 구현은 단순해 보이지만, latency와 failure diagnosis에서 약합니다.
세 번째 단계는 record schema입니다. 최소한 attempt id, robot hand model, sensor layout, calibration version, task phase, object/SKU id, selected grasp, measured contact patch, normal/shear force summary, slip event, action output, safety intervention, final outcome을 저장해야 합니다. 제조 셀에서는 이 record가 곧 QA trace입니다. 연구실에서는 한 번의 성공 영상이 설득력을 가질 수 있지만, 생산 라인에서는 실패가 반복될 때 원인을 좁히는 능력이 더 중요합니다. 따라서 VLA와 촉각 통합 실험의 결과표는 success rate 하나가 아니라 failure type distribution, retry count, damage rate, cycle time variance, operator intervention frequency를 함께 보여야 합니다.
네 번째 단계는 작은 테스트 프로토콜입니다. 처음부터 모든 물체와 모든 손 동작을 다루면 실패 원인을 해석하기 어렵습니다. 먼저 single contact acquisition, stable hold, controlled release, contact switch, recovery after slip 같은 원자 태스크를 정의합니다. 그 다음 두세 개의 원자 태스크를 묶어 sequential manipulation을 만들고, 마지막에 Cosmax형 first grasp -> in-hand rearrangement -> second grasp 시나리오로 확장합니다. 이렇게 해야 VLA와 촉각 통합이 실제로 어떤 failure mode를 줄였는지 확인할 수 있습니다. 특히 손안 조작과 다물체 파지는 성공/실패가 한 순간에 결정되지 않고, 여러 contact transition의 누적으로 결정됩니다.
다섯 번째 단계는 하드웨어와 유지보수 조건을 실험 변수로 포함하는 것입니다. 같은 알고리즘도 젤 표면 마모, 패드 오염, 케이블 장력, 센서 교체 후 calibration, 손가락 backlash, 온도, 표면 습도에 따라 다르게 작동합니다. 따라서 실험 로그에는 software version뿐 아니라 pad age, cleaning state, calibration time, replacement event, fault code를 기록해야 합니다. 이 정보가 있어야 모델 성능 저하와 센서/기구 열화를 분리할 수 있습니다. 제조용 tactile robotics는 policy benchmark가 아니라 운영 시스템이기 때문에, maintenance variable은 주변 정보가 아니라 핵심 state입니다.
마지막 단계는 의사결정 기준입니다. VLA와 촉각 통합을 도입했을 때 성공률이 올라가는지만 보지 말고, 어떤 실패가 줄었는지를 확인해야 합니다. perception failure가 줄었는지, contact acquisition failure가 줄었는지, force closure 부족이 줄었는지, execution-time slip이 줄었는지, 아니면 operator override가 줄었는지 분리해야 합니다. 이 분해가 가능해야 다음 투자가 정해집니다. 센서를 바꿀지, 손을 바꿀지, controller를 바꿀지, simulator를 보강할지, 데이터 수집을 늘릴지가 명확해집니다.
| 구현 질문 | 확인할 로그 | 통과 기준 |
|---|---|---|
| 상태가 관측되는가 | sensor packet, calibrated value, contact frame | controller와 QA가 같은 값을 읽음 |
| 제어 루프가 분리되는가 | fast reflex, mid-level planner, slow policy timestamp | 빠른 slip 사건과 느린 task decision이 충돌하지 않음 |
| 실패가 분류되는가 | failure type, phase, intervention note | 실패 원인이 3개 이하 후보로 좁혀짐 |
| 유지보수가 기록되는가 | pad age, calibration version, replacement event | 성능 저하와 hardware drift를 분리 가능 |
| 제조 KPI와 연결되는가 | cycle time, damage rate, retry count, downtime | 연구 성공률이 운영 지표로 번역됨 |
참고문헌
- Brohan, A., Brown, N., et al. (2023). RT-1: Robotics Transformer for real-world control at scale. RSS 2023. arXiv:2212.06817. scholar
- Brohan, A., Brown, N., et al. (2023). RT-2: Vision-Language-Action models transfer web knowledge to robotic control. CoRL 2023. arXiv:2307.15818. scholar
- Kim, M. J., Pertsch, K., Karamcheti, S., et al. (2024). OpenVLA: An open-source Vision-Language-Action model. arXiv:2406.09246. scholar
- Octo Model Team. (2024). Octo: An open-source generalist robot policy. arXiv:2405.12213. #55 scholar
- Black, K., Brown, N., et al. (2024). pi0: A Vision-Language-Action flow model for general robot control. arXiv:2410.24164. #2 scholar
- Google DeepMind. (2025). Gemini Robotics: Bringing AI into the physical world. arXiv:2503.20020. scholar
- Open X-Embodiment Collaboration. (2024). Open X-Embodiment: Robotic learning datasets and RT-X models. ICRA 2024. arXiv:2310.08864. scholar
- Lipman, Y., Chen, R. T. Q., Ben-Hamu, H., Nickel, M., & Le, M. (2023). Flow matching for generative modeling. ICLR 2023. arXiv:2210.02747. scholar
- Yu, J., Liu, H., Yu, Q., Ren, J., Hao, C., Ding, H., Huang, G., Huang, G., Song, Y., Cai, P., Lu, C., & Zhang, W. (2025). ForceVLA: Enhancing VLA models with a force-aware MoE for contact-rich manipulation. NeurIPS 2025. arXiv:2505.22159. #1 scholar
- Huang, J., Wang, S., Lin, F., Hu, Y., Wen, C., & Gao, Y. (2025). Tactile-VLA: Unlocking vision-language-action model's physical knowledge for tactile generalization. arXiv:2507.09160. scholar
- Helmut, E., Funk, N., Schneider, T., de Farias, C., & Peters, J. (2025). Tactile-conditioned diffusion policy for force-aware robotic manipulation. ICRA 2026. arXiv:2510.13324. scholar
- Various. (2026). VLA systematic review. Information Fusion (Elsevier). https://doi.org/10.1016/j.inffus.2025.103148. scholar
- Various. (2025). What matters in building VLA models. Nature Machine Intelligence. https://doi.org/10.1038/s42256-025-01168-7. scholar
- Various. (2025). Diffusion models for robotic manipulation survey. Frontiers in Robotics and AI. https://doi.org/10.3389/frobt.2025.1606247. scholar
- Physical Intelligence. (2025). pi0.5: A VLA model and training recipe for post-deployment improvement via RLEF. arXiv preprint. arXiv:2504.16932. #4 scholar
- NVIDIA. (2025). GR00T N1: An open foundation model for generalist humanoid robots. arXiv preprint. arXiv:2503.14734. scholar
- NVIDIA 2026. GR00T N1.5: Advancing humanoid robot foundation models. GTC 2026. scholar
- Figure AI. (2025). Helix: A vision-language-action model for full humanoid control. Company technical report. scholar
- Physical Intelligence. (2025). pi0 human-to-robot transfer: Human co-finetuning for generalization. Technical report. scholar
- Various. (2025). EgoVLA: Egocentric human video pretraining for robot VLA. arXiv preprint. scholar
- Various. (2025). PhysBrain: Physical world fine-tuning of VLMs via 3M VQA from Ego4D. arXiv preprint. scholar